在Kubernetes上用ClusterControl运行Galera集群
发布于:2021-01-22 14:30:21
在我们的“MySQL on Docker”博客系列中,我们继续探索如何使Galera集群在不同的容器环境中顺利运行。在容器或裸机中运行数据库服务时,最重要的一点是消除数据丢失的风险。我们将看到如何利用Kubernetes中一个很有前途的特性StatefulSet,它以一种更可预测和可控的方式编排容器部署。
在我们之前的博客文章中,我们展示了如何在Docker中使用Kubernetes作为编排工具部署Galera集群。然而,这仅仅是关于部署。运行数据库需要的不仅仅是部署—我们需要考虑监视、备份、升级、故障恢复、拓扑更改等等。这就是ClusterControl进入画面的地方,因为它完成了堆栈并使其准备就绪。简单地说,Kubernetes负责数据库的部署和扩展,而ClusterControl则负责填充缺少的组件,包括配置、监视和日常管理。
Docker上的ClusterControl
这篇博客文章描述了ClusterControl如何在Docker环境中运行。Docker映像已经更新,现在在最新的stable分支中提供了标准的ClusterControl包,并对容器编排平台(如Docker Swarm和Kubernetes)提供了额外的支持,我们将在下面进一步描述这一点。您还可以使用映像在独立Docker主机上部署数据库集群。
Github存储库或Docker Hub页面上的详细信息。
Kubernetes的聚类控制
更新后的Docker映像现在支持自动部署Kubernetes调度的数据库容器。这些步骤类似于Docker Swarm实现,其中用户决定数据库集群的规格,ClusterControl自动执行实际部署。
ClusterControl可以部署为ReplicaSet或StatefulSet。因为它是一个单独的实例,所以任何一种方法都是有效的。唯一显著的区别是使用StatefulSet更容易识别容器,因为它提供了一致的标识符,如容器主机名、IP地址、DNS和存储。ClusterControl还为新的群集部署提供服务发现。
要在Kubernetes上部署ClusterControl,建议使用以下设置:
将Kubernetes插件(例如NFS、iSCSI)支持的集中式持久卷用于以下路径:
/etc/cmon.d-ClusterControl配置目录
<var cmon和dcps数据库
为此pod创建2个服务:
一个用于POD(暴露端口80和3306)
一个用于对外通信(暴露端口80、443,使用NodePort或LoadBalancer)
在这个例子中,我们将使用简单的NFS。确保准备好NFS服务器。为了简单起见,我们将在3主机Kubernetes集群(1个主节点+2个Kubernetes节点)上演示此部署。不过,我们建议至少运行3个Kubernetes节点,以将丢失仲裁的风险降至最低。
有了它,我们可以像这样部署ClusterControl:
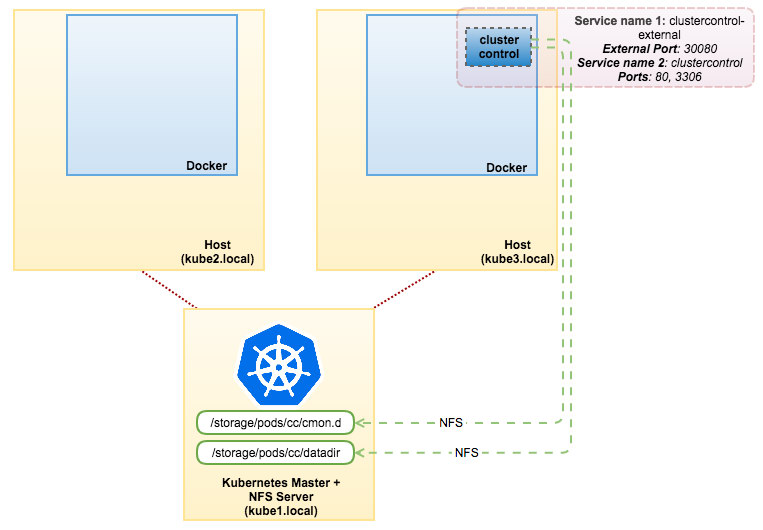
在NFS服务器(kube1.local)上,安装NFS服务器和客户端包并导出以下路径:
/storage/pods/cc/cmon.d-映射到/etc/cmon.d
/storage/pods/cc/datadir-映射到/var/lib/mysql
确保重新启动NFS服务以应用更改。然后创建pv和pvc,如cc pv所示-聚氯乙烯yml地址:
$ kubectl create -f cc-pv-pvc.yml
我们现在准备开始一个集群控制舱的复制品。发送抄送-日元致库伯内特斯大师:
$ kubectl create -f cc-rs.yml
ClusterControl现在可以在任何Kubernetes节点的端口30080上访问,例如,http://kube1.local:30080/clustercontrol。使用这种方法(ReplicaSet+PV+PVC),如果物理主机宕机,clustercontrolpod将能够生存。Kubernetes将自动将pod调度到其他可用的主机上,ClusterControl将从最后一个通过NFS可用的现有数据集引导。
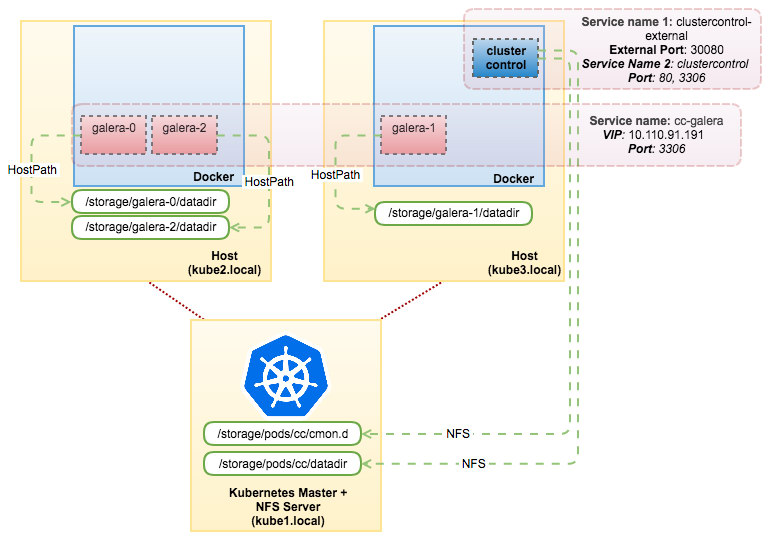
Kubernetes上的Galera群
如果要使用ClusterControl自动部署功能,只需将以下YAML文件发送到Kubernetes主机:
$ kubectl create -f cc-galera-pv-pvc.yml $ kubectl create -f cc-galera-ss.yml
上面的命令告诉Kubernetes使用名为“centosssh”的通用基本映像创建3个pv、3个pvc和3个pod,作为StatefulSet运行。在本例中,我们要部署的数据库集群是MariaDB 10.1。一旦容器启动,它们将自己注册到ClusterControl CMON数据库。然后ClusterControl将获取容器的主机名,并根据已传递的变量启动部署。
您可以直接从ClusterControl UI检查进度。一旦部署完成,我们的体系结构将如下所示:
HAProxy作为负载均衡器
Kubernetes在将流量分发到后端pods时,通过服务组件提供了内部负载平衡功能。如果平衡(最少的连接)适合您的工作负载,这就足够了。在某些情况下,由于死锁或严格的先读后写语义,应用程序需要向单个主机发送查询,因此必须创建另一个Kubernetes服务,并使用适当的选择器将传入连接重定向到一个且仅一个pod。如果这个pod坏了,当Kubernetes将其再次调度到另一个可用节点时,就有可能出现服务中断。我们在这里要强调的是,如果您想更好地控制发送到后端Galera集群的内容,HAProxy(甚至ProxySQL)之类的东西在这方面相当不错。
您可以将HAProxy部署为两个pod的ReplicaSet,并使用ClusterControl来部署、配置和管理它。只需将此YAML定义发布到Kubernetes:
$ kubectl create -f cc-haproxy-rs.yml
上面的定义指示Kubernetes创建一个名为cc haproxy的服务,并运行“severlnines/centos ssh”映像的两个副本,而不进行自动部署(AUTOu deployment=0)。然后,这些pod将连接到clustercontrolpod并执行自动无密码SSH设置。现在需要做的是登录到ClusterControl UI并开始部署HAProxy。
首先,检索HAProxy pods的IP地址:
$ kubectl describe pods -l app=cc-haproxy | grep IP IP: 10.44.0.6 IP: 10.36.0.5
然后将该地址用作ClusterControl下的HAProxy地址->;选择DB cluster->;Manage->;Load Balancer->;HAProxy->;Deploy HAProxy,如下所示:
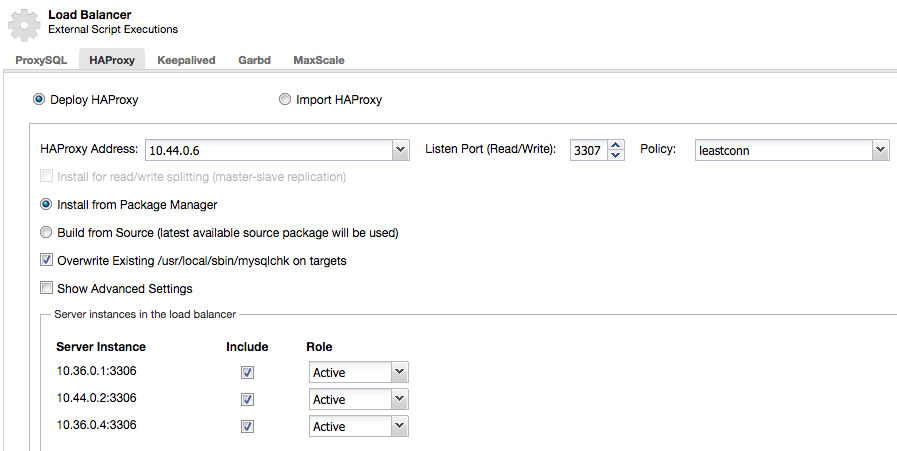
**对第二个HAProxy实例重复上述步骤。
一旦完成,我们的Galera集群可以通过内部端口3307(Kubernetes网络空间内)或外部端口30016(外部世界)上的“cc haproxy”服务进行访问。连接将在这些HAProxy实例之间进行负载平衡。在这一点上,我们的体系结构可以如下所示:
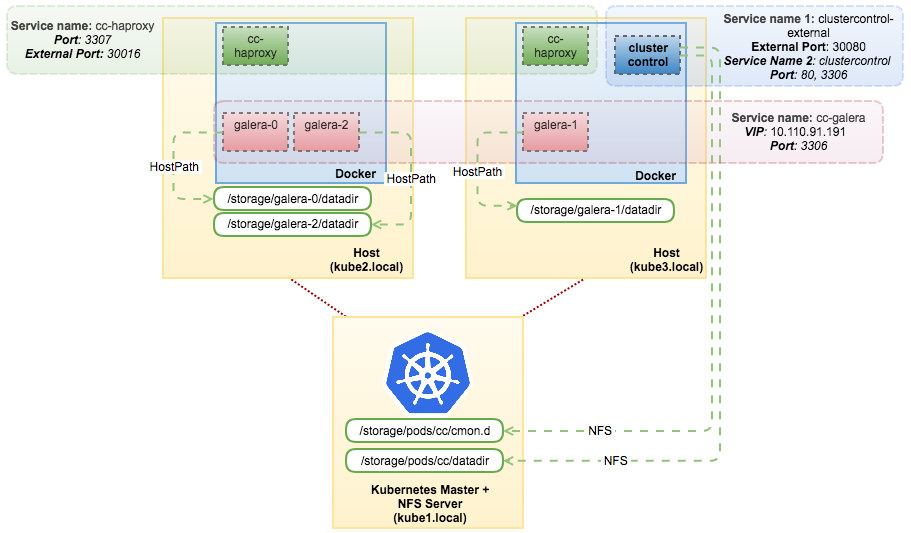
通过此设置,您可以最大限度地控制在Docker上运行的负载平衡Galera集群。Kubernetes通过支持有状态的服务编排,带来了一些好东西。
一定要试一试。我们很想听听你们相处得怎么样。
免责声明
ClusterControl Docker对Kubernetes上Galera群集的映像支持目前不是官方ClusterControl产品的一部分。这是一个开源项目,您可以在我们的Github页面上跟踪和贡献它。
作者介绍
